思维导图
视频讲解
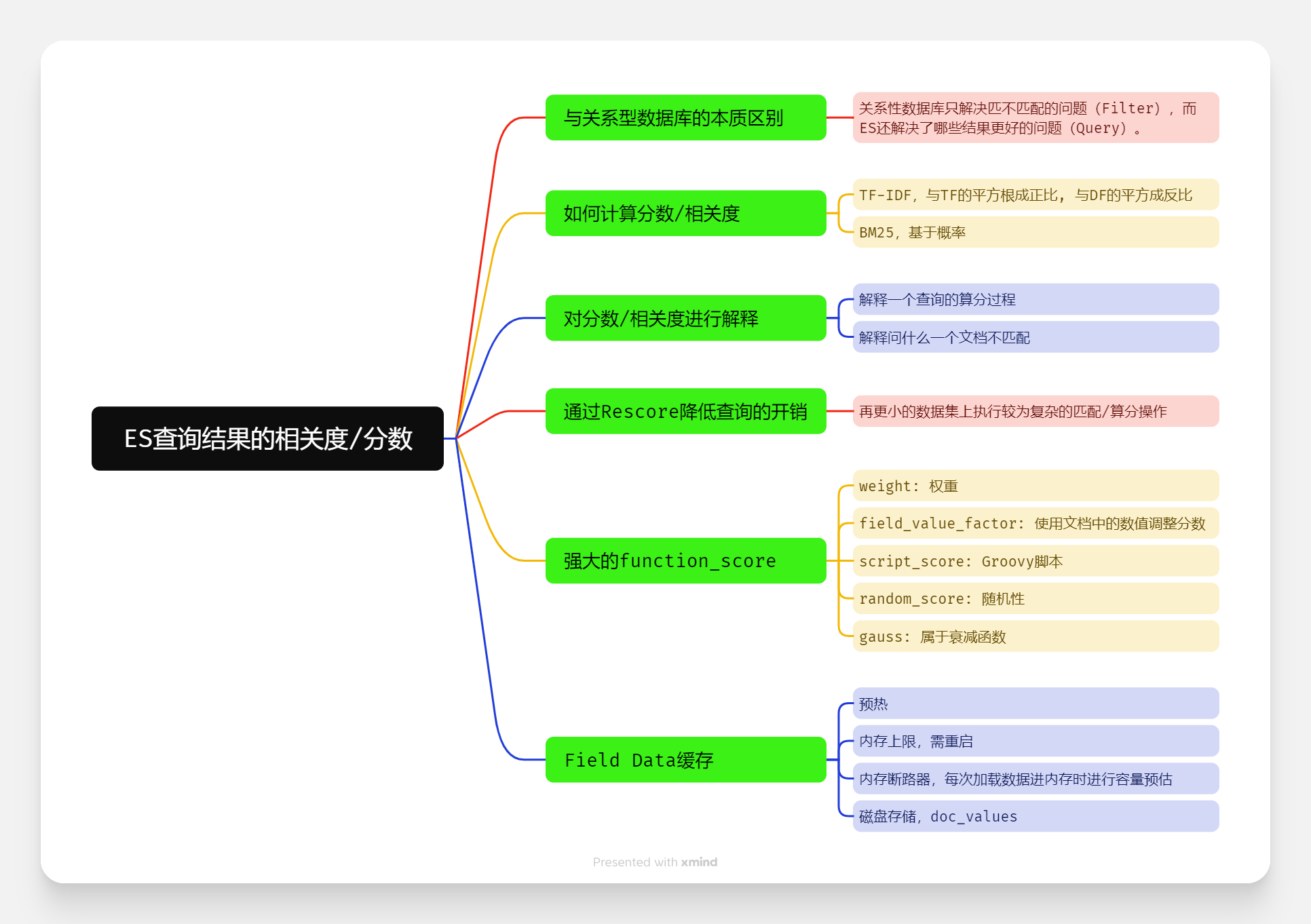
与关系型数据库的对比
所有存储引擎都能够处理查找文档/记录的请求.
关系型数据库通过LIKE 'keyword%'或正则表达式来支持一些复杂的字符串匹配需求.
ES除了有支持丰富的匹配(在ES中称作Filter)能力, 还能够计算文档的分数/相关度(在ES中与Query相关), 让用户查询到更好的结果.
分数/相关度是如何计算的?
ES中预置了多种模型, 比如TF-IDF、BM25等, 其中TF-IDF最为熟知, 也是ES的默认算分模型.
TF-IDF模型的计算方式:
对于文档中的每一个Term, 计算$\sqrt{TF} * IDF^2 * norm(d, field) * boost(t)$.
其中最终分值与TF的平方根成正比, 与DF的平方成反比.
BM25模型的计算是基于概率的, 原理更加复杂.
Boosting
针对Bool类型的查询, 每个条件的权值肯定不相同, 例如: A(重要) | B, 则A应该给与更高的权值.
需要注意的是Boosting所设置的权值并不是绝对, 计算时经过了标准化, 仅表示相对的概念.
Boosting可以在索引(Insert)时就把Term的权值加大, 但是这样会极其的不灵活, 如果需要修改权值需要重新索引.
所以一般更推荐在查询时对某些条件进行Boosting, 这样非常灵活, 也不容易出现Boosting放大的问题.
在部分查询时还可以通过
field^n来表达Boosting的含义.
对分数/相关性进行解释
ES提供了相关的API对分数/相关性进行解释:
- 解释一个查询的分数计算过程.
- 解释一个文档为什么不匹配某个查询.
通过Rescore降低查询的开销
如果你的查询需要消耗大量的资源/耗费大量的时间, 那么在全量的数据集上完成这件事是很困难的.
这时我们就可以通过Rescore降低查询的开销:
- 先进行初步的Query(这部分的开销较小, 在全量的数据集上进行).
- 在进行后续的Rescore(这部分的开销较大, 在上次查出来的数据集上进行).
- 调整两个步骤的得分在总得分中的比重.
使用更强大的function_score
- weight: 给一个条件带上权重.
- field_value_factor: 使用文档中的数值调整分数, 比如: 评论数、点赞数.
- script_score: 书写Groovy脚本来计算分值.
- random_score: 增加一些随机性.
- gauss: 属于衰减函数(Decay Function), 随距离的增加/时间的推移逐步降低文档的得分/相关性.
每个Function以及原查询的分数如何组合可以通过score_mode和boost_mode进行控制.
使用脚本进行排序
针对一些复杂的排序场景可以使用Groovy脚本来完成.
Field Data缓存
ES在做很多查询时需要用到一个字段的所有Term的集合, 比如: 聚合(aggregation).
而这部分是需要缓存到内存中的, 而加载这部分缓存又是比较耗时的操作, 所以最好进行预热/配置字段的fielddata为eager.
当然站在运维的角度, 肯定避免要避免一些内存溢出、内存频繁换出的现象:
- 设置内存上限: 需要重启进行调整.
- 使用内存断路器(Circuit Breaker): 在预估加载内存超过上限时, 向客户端报错. 可以动态调整.
- 使用磁盘存储: 在索引时就构建这部分数据(doc_values), 并存储到磁盘上, 当然性能肯定会受到一定的影响.
参考资料
- ElasticSearch In Action (English Version)