思维导图
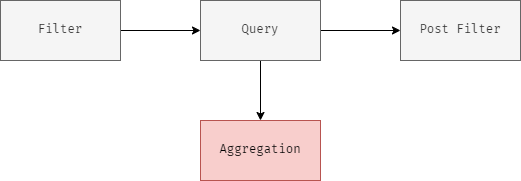
聚合的执行过程
指标型聚合
指标型聚合和SQL中的聚合函数有些类似, 例如: 求均值、最大值.
可以通过stats、extended_stats得到一些常见的数值型指标, 其中extended_stats返回的指标更多, 例如标准差、方差.
如果你的数据集很大, 那么想要准确的计算一些指标是很困难的; 这时就可以选择牺牲一定的准确度来换取更好的性能(执行时间、内存消耗).
通过百分位数(percentiles)和基数(cardinality, 不重复的值的个数)来说明如何做这种权衡:
- 在使用percentiles时, 可以通过调整
compression参数, 让更多的样本参与到计算中来. - 在使用cardinality时, 可以通过调整
precision_threshold参数, 来调整HyperLogLog所占用的内存大小.
在默认情况下, percentiles和cardinality聚合就已经是一个估算值了.
分桶型聚合
分桶型聚合和SQL中的GROUP BY有些类似, 例如: 你有网站的访问数据, 那么根据国家进行分桶, 然后再计算基数就是一个不错的场景.
进行分组时, 需要考虑到最终组的数量, 如果一个字段是连续的并且为数值型, 那么它的基数可能会非常大, 分组后毫无价值.
所以一般情况下, 对于字符串字段(基数较小)使用terms进行聚合, 对于数值型字段(基数较大)使用range和histogram进行聚合会比较合适.
聚合的嵌套
与SQL中的子查询类似, 将聚合进行嵌套能够实现更加复杂的功能.
Result Grouping
在Google一个关键词时, 可能会有多个类别的内容都包含该关键词, 但你绝不会一直看到一个类别的网站, 而是每个类别都会出现.
在ElasticSearch中, 这种技术被称作Result Grouping, 展示每个分组中最相关的几条内容.
书写查询时需要用到的聚合是top_hits, 如果你需要为一个电商网站的搜索书写一个查询:
- 使用
terms聚合根据category进行分桶, 使用size限制桶的数量, 默认按桶内文档数排序. - 使用
top_hits聚合(嵌套)从每个桶内取购买量最多的商品, 用sort指定排序规则, 用size限制每个桶内文档数.
最终可以得到以下查询:
{
"aggregations": {
"category_buckets": {
"terms": {
"field": "category",
"size": 5
},
"aggregations": {
"best_products": {
"top_hits": {
"sort": {
"buy_count": "desc"
}
},
"size": 2
}
}
}
}
}
单桶聚合
- 可以创建一个
global聚合作为需要执行的聚合的parent, 这样需要执行的聚合的输入就会变为全部文档. - 可以创建一个
filter聚合作为需要执行的聚合的parent, 这样就可以不影响query的结果, 仅为需要执行的聚合过滤文档. - 可以创建一个
missing聚合, 这样就可以得到字段缺失的桶.
参考资料
- ElasticSearch In Action (English Version)